

The team has really pulled together quite the game experience for our Game-Only Edition that is coming out… well, just stay tuned this week 🙂 Please help us by playing the Primoid and let us know your thoughts and issues you run into in the Contributor Community Discord server (find access to it on the Steam Forums here once you log in!). Better yet, build or improve existing areas with the Crush2D tools and show us your ideas! If we like them enough, we’ll see about integrating them and giving you official credit in the game.
Changelog highlights:
- Massively improved all existing areas of the Primoid
- Added new very WIP South Hub and Mountain areas
- New Wrangleoid minigame Planetoids
- Automatic save game system
- Improved Pioneer locomotion: proper jump, slide, uphill walk etc
- Completely overhauled and much nicer sounds for material impacts, etc
- Reverb system with echo depending on distance to walls
- New much more robust physics solver and other performance improvements
- Activity editor target system and IO system to easily make everything trigger anything without code
- Redesigned background art in lots of the old Planetoids
- New loot system with tiered weapons and different new loot items
- Lots of new and improved Blueprints (including new enemies like zombies!)
- As always, more bug and crash fixes than we can list. See the repo echo bot for details
If the physics-based, real-time tactical, sidescrolling gameplay of Cortex Command is up your alley, then you should definitely not miss out on fellow indie dev VAP Games’ Intrusion 2! It features the best use of physics in Flash that I’ve ever seen, and was made by a sole developer in the middle of Russia (with help from a talented musician as well):
http://www.intrusion2.com/
The trailer speaks for itself; there’s also a demo and you can buy the DONE game today (what a concept!). I appreciate when I can see quality and passion poured into a project, so I am eager to spread the word about this gem. Now go check it out!
 So here’s an update on what we’ve been working on. There was a bit of a slump in productivity in June as we moved our offices, but we’ve picked up the pace in the past week.
So here’s an update on what we’ve been working on. There was a bit of a slump in productivity in June as we moved our offices, but we’ve picked up the pace in the past week.
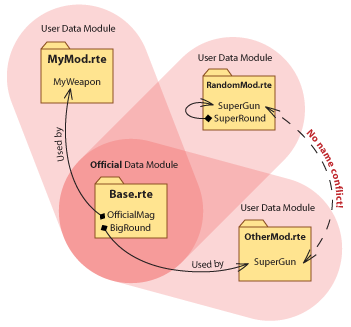
A big problem with making mods for Cortex Command has been that any new names you defined in your data module could collide with ones found in any other random mod out there. So, if anyone tried to load both your and that other mod at the same time, very strange and unexpected things would occur (someone else’s arms and legs on your guy!). Or just crash the game with little clue as to what conflict caused it.
So we took a break from working on the new editors to solve this problem. Now, user made data modules form their own ‘name-spaces’, and thus can define whatever names they want, as long as they don’t conflict with anything in the official Base.rte module. This means your SuparGun will coexist peacefully with that other guy’s SuparGun, as long as you both follow some simple rules:
- Your instance names can’t be the same as anything in the official data module Base.rte
- In your own data module you can use anything defined in the official module, Base.rte. You can safely make copies or reference them as you wish.
- You CAN’T, however, use anything defined in any data module other than the official one, or the one you’re working on. This would cause an interdependency between two user made data modules, and will cause errors if they get separated. Just put everything dependent on each other into one module… you can organize it thoroughly. Look at how Base.rte is organized for tips.
Back to work on the Scene and Gib Placement editors!
Ok, after a few days of thinking hard and long about what to do with the data file reading/saving system, I’ve finally come to a decision and plan for what to implement.
The CC engine originally used a very simple way of exposing every single object’s variables to the data files by serializing out their values in a certain order. The order of these values determined which variable they belonged to. It looks something like this:
MOSprite
MovableObject
Object
Fire Ball 3
5
Vector
0
0
Vector
0
0
# Scale
1.0
# The rest threshold in ms
500
# Lifetime, 0 = unlimited
250
# Sharpness factor
0.1
# Whether or not this hits other MO:s
1
# Whether or not this gets hit by other MO:s
0
ContentFile
Base.rte/Effects/Effects.dat#Fireball03
11
# Sprite offset
Vector
-9
-9
# Horizontally flipped
0
# Rotation angle in radians.
0
# Angular velocity in radians / s.
60
# Entry Wound Emitter
None
# Exit Wound Emitter
None
Atom
Vector
0
0
Material
%Air
Color
0
0
0
# Trail Max Length
0 # Initial framerate in fps. If 0, will be animated over the lifetime
0
Note the use of indentation to keep track of the class hierarchy, and # to mark line comments.
This is a very rickety and fragile way of storing game data. Leaving out or mixing up any values would make the order, and therefore the reading procedure get messed up in sometimes hard-to-catch ways. As soon a member variable is added to a class, the data files had to be updated with values for this added variable – Bad. But this old crappy way worked on the small proof-of-concept scale of the current CC Test build!
So what I’ve been thinking about is wheteher to completely replace the current system with something new and probably XML-based, or to just improve upon the existing code, or do something in between. I started going down the path of replacement with an article and sample code of Frederic My’s article in Game Programming Gems 4. It’s a very robust and complete system for custom RTTI (real time type identification, or reflection) and properties-based data persistence. Its files look like this:
<class name=’CRefCount’ base=”>
</class>
<class name=’CPersistent’ base=’CRefCount’>
<prop name=’Name’ type=’String’/>
</class>
<class name=’CEditorSceneItem’ base=’CPersistent’>
<prop name=’Deleted’ type=’Bool’/>
<prop name=’Expanded’ type=’Bool’/>
<prop name=’Prev Parent’ type=’String’/>
<prop name=’EditorObj’ type=’SP’/>
<prop name=’Subitems’ type=’Fct’/>
</class>
<class name=’CEditorObj’ base=’CPersistent’>
<prop name=’Selected’ type=’Bool’/>
<prop name=’Deletable’ type=’Bool’/>
<prop name=’Draggable’ type=’Bool’/>
<prop name=’DropTarget’ type=’Bool’/>
<prop name=’Renamable’ type=’Bool’/>
<prop name=’EngineObj’ type=’SP’/>
</class>
<class name=’CEditorNode’ base=’CEditorObj’>
</class>
<data class=’CEditorNode’ id=’0x16C4D50′>
scene root
false
false
true
true
true
0x16C3080
</data>
</xml>
Note how he definies how the classes and properties are structured before describing the values. He also uses the current pointer addresses as the unique identifiers for the object instances saved out.
It took some pondering to conclude that I’d probably spend more time gutting my existing code and replacing it with an adjusted and adapted version of My’s sample code to make it worth it. I also don’t have much use for some of the benefits of his techniques, since I’ve already engineered my code to work around the shortcomings of my original techniques.
After reading this excellent thread by the Moonpod guys on XML, I had to reconsider once more whether I should go with my own format or some XML flavor:
http://www.moonpod.com/board/viewtopic.php?p=15369#15369
Although the DTD’s are a compelling and really interesting feature, I’ve decided that readability and ease-of-editing are my highest priorities. XML just isn’t very readable or convenient to edit with all those closing tags and different ways of formatting things. I prefer to keep things simple and with little room for my formatting obsessive-compulsiveness to freak out when I change my mind about pointless conventions.
Another big priority is to keep things very self-documenting, and that was why I actually didn’t like My’s way of keeping the property definintions in a separate place in the file. When I’m editing something, I’d like for the documentation to be right there in some way so i don’t have to look it up in the code or somewhere elese. This’ll be even more important for any modders who want to change things around in these files and don’t have the code to refer to.
Finally, the last important benefit I’m seeking is to be able to omit as much redundant data as possible in these files. I found that even in the CC test, I ended up with really long files to scroll through, and much of it was just default value filler to keep the order intact. If I can just keep the defaults of an intialized and read object by omitting those values in the data files, I’ll be much better off. This’ll also help keep old data files working with new versions of the code since they’ll just define their old values and leave loaded objects’ undefined properties with safe default values.
Anyway, if you’re still reading this, here’s the way the new format I’ve come up with will look like:
Parent = MOSprite
Parent = MovableObject
Parent = Object
InstanceName = Fire Ball 3
Mass = 5 # kg
Position = Vector
X = 0
Y = 0
Velocity = Vector
X = 0
Y = 0
Scale = 1.0
RestThreshold = 500 # in ms
Lifetime = 250 # ms, 0 means unlimited
SharpnessFactor = 0.1
HitsMOs = 1
GetsHitByMOs = 0
SpriteFile = ContentFile
FilePath = Base.rte/Effects/Effects.dat#Fireball03
Frames = 11
SpriteOffset = Vector
X = -9
Y = -9
HorizontallyFlipped = 0
Rotation = 0 # radians
AngularVelocity = 60 # radians / s
EntryWoundEmitter = None
ExitWoundEmitter = None
Atom = Atom
Offset = Vector
X = 0
Y = 0
Material = Material
%Air
AtomColor = Color
R = 0
G = 0
B = 0
TrailMaxLength = 0
InitialFramerate = 0 # fps. If 0, will be animated over the lifetime
# are still comments. Everything before an equal sign is the property’s name, and everything after is the corresponding value. % means to set the entire object’s data to that of one which is already defined. Properties can be in any order, or omitted. The big constraint is that the tab indentation now matters, so that’s a source for errors, but I think it’s a good tradeoff to having some kind of nested opening and closing brackets (e.g. { and }) all over the place.
That’s all for now… my tired brain going to bed. Tomorrow is all about retrofitting the old code with this crazy new system.